WTH is Planned Failover for Azure Storage?
Earlier this month, Microsoft announced a preview of Planned Failover for Azure Storage. Unplanned failover has been available for some time, so what’s the difference? Let’s take a look.
What is Planned Failover for Azure Storage?
Planned Failover allows you to failover Geo Redundant and Geo Zone Redundant storage to their secondary region in a planned manner. In this scenario, traffic is redirected to use the secondary region, but this is done in a controlled fashion where the following process is followed:
- The primary region becomes read-only.
- Replication of all data from the Primary to Secondary region is completed.
- DNS entries for storage endpoints in the secondary region are promoted to become the primary endpoints.
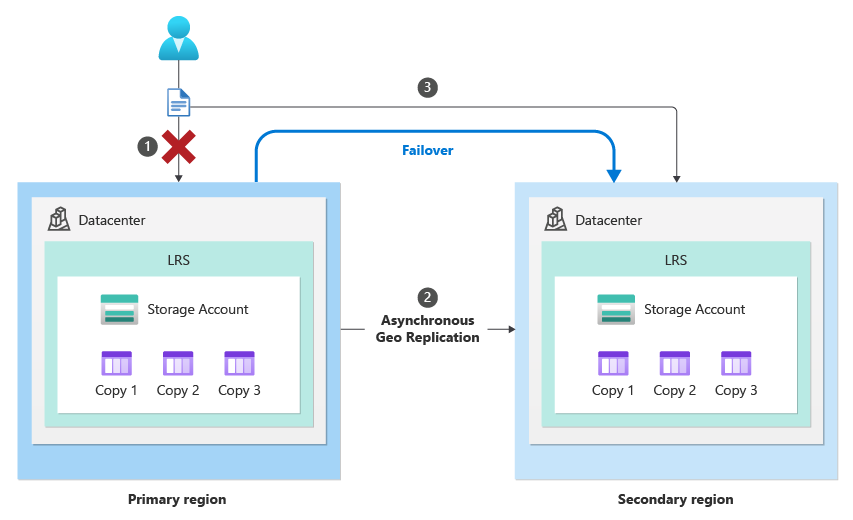
Because this is a controlled process that can only be done when both storage accounts are online, the secondary region always has a full replica of the data before failover, ensuring there is no data loss. This is the opposite of an unplanned failover, where the primary account may not be online. In an unplanned failover, the switch to using the secondary region occurs immediately without waiting for replication to complete, which can lead to data loss.
Because both primary and secondary regions are online for the process, this also means that failing back to the primary region is just the reverse of the above method. This again differs from an unplanned failover, where the failover effectively breaks the replication and you will need to re-replicate the data before failing back.
How does Planned Failover Work?
Initiating a failover can be done via the portal or the CLI and uses the same process as an unplanned failover, aside from indicating that the type of failover is “planned” rather than “unplanned”:
az storage account failover \
--resource-group <resource-group-name> \
--name <storage-account-name> \
--failover-type planned
We can then monitor the status of the failover using the CLI or Portal:
az storage account show \
--resource-group <resource-group-name> \
--name <storage-account-name> \
--expand geoReplicationStats
Once the failover is complete, the storage account can be used normally, but the primary region will now be the previous secondary region.
Why Would I Want to Use Planned Failover
Planned failover can only be used when both storage accounts are online, so it cannot be used in a real disaster where the primary region is offline. Instead, this feature could be used in more proactive scenarios such as:
- Failover testing and planning
- Pro-active failover before a potential disaster
- Failure of other resources necessitated failover, but storage is still online
Both planned and unplanned failovers use the same mechanism and do not require any additional configuration other than ensuring your account uses GRS/GZRS. Given this, the appropriate failover mechanism can be used based on the issues at the time rather than needing to determine upfront which will be used.
What Issues Does Planned Failover Have?
There are a few things to be aware of when looking to use this feature:
- It’s in preview, so it’s not suitable for production use yet; it is also in limited regions.
- Failover takes around an hour to complete replication and change DNS to point to the secondary region
- After a planned failover, a storage account’s Last Sync Time (LST) value might appear stale or be reported as NULL when Azure Files data is present. See here for details.
